How to log functionally at Java
Introduction
Logs give us insight how application worked at specific time. Therefore logging is vitally important for any application. And logging framework exists almost at any language.
Today I discuss about logging practices that I use at functional coding style.
Let’s look on following code snippet:
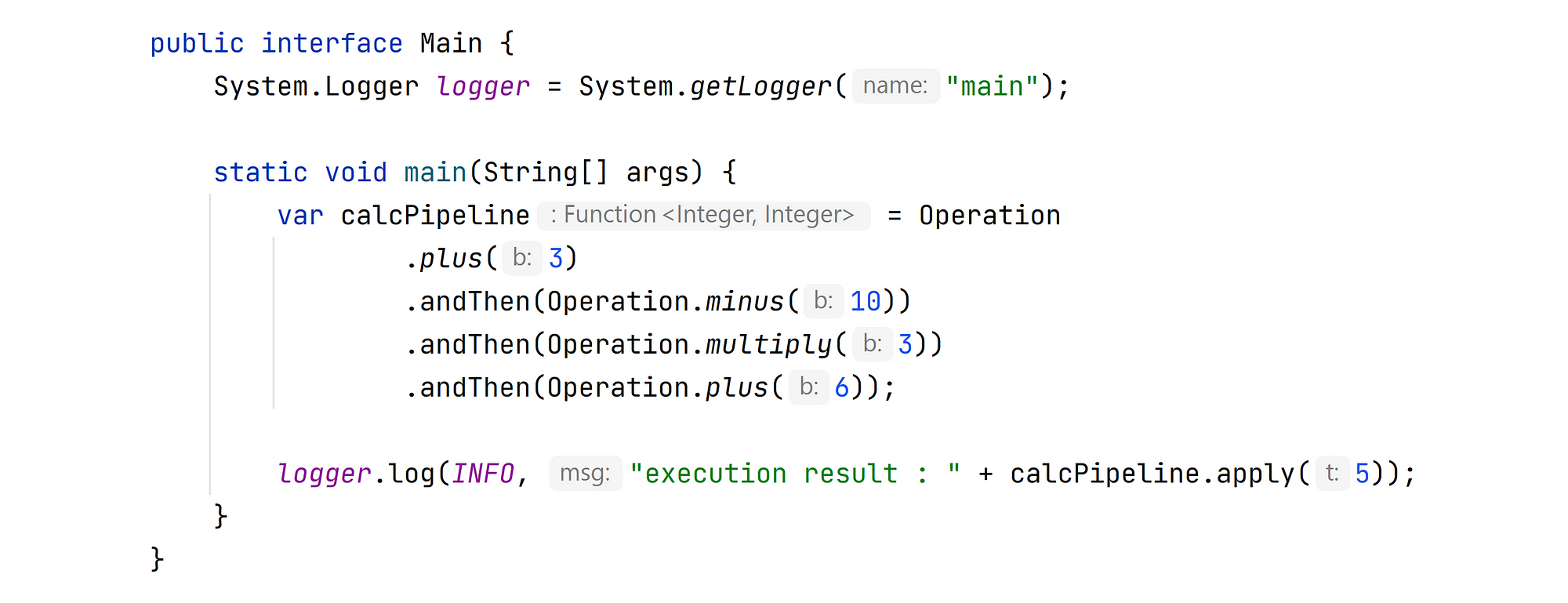
I would like to log operation result after each execution step at calcPipeline. Where I should place log statements?
Usually all logs statements are placed in methods at Object-Oriented programming (OOP). You could apply such rule at Functional Programming (FP) too.
But is it functional way to put all log statements to lambda body?
Read further to get answer for this question.
What do we log?
If you get any application logs and try to categorize log messages I think you end up with two log message types:
- How program executes
- What values are computed
The first type is describe running processes at program. For example, starting scheduled job. Reading such logs we understand that program is running and could track process execution flow.
The second type is describe processes execution results. For example, math operation execution result. Reading such logs we can verify that program algorithms works correctly.
How to log function execution?
Let’s have a look what function consists of and than we dive into logging function execution.
Function consists three part:
- Input value
- Output value
- Function body
Function receives input value than performs some computation at its body and return computation result as output value.
According to function structure there are 3 places to log function execution:

Let’s go through all log places.
Log internal process details
Function body consists of single expression or statement block. It is the place where some computation is performed. You can log some information about process details. For example, debugging information about intermediate computation results.
So, where do you place log statements at such case?
You are free to place anywhere you want according to your coding style. There is only one restriction — logger instance should be accessible and initialized at function execution time.
I have used Operation interface at article’s introduction. Here is interface implementation:

Now I add log statements to lambda body:

Code looks like an imperative one and there is no differents here between OOP style and FP one.
Log input and output values
Another places to log are similar to each other. Both represent the same function that receive some value as input, perform logging and return input value as output one. Here is code:

PeekLog interface extends supplier function and return logger instance when method get is invoked. Method of creates PeekLog function. Method log performs logging. Its implementation is inspired by peek method from java.util.stream.Stream interface.
Let’s look on code snippet from introduction part:
Improve code by adding log output:

Using PeekLog function we can embed log statements to method’s chain at functional code style.
Logable function
I think PeekLog function is appropriate for many cases. But from my point of view there are some issues when PeekLog is used at this way:
- Required to use local variable
- Hard to read code
How to solve such issues?
The first decision is straightforward: move function composition into method in Operation interface:

Let’s look at main method after code moving:

Code become concise and looks pretty enough at main method. But such decision have some disadvantages:
- logging input and output value is not Operation interface resposibility due to it is out from function body scope
- you can not reuse such decision for another function
- we have to use local variable in order to log pipeline execution result
The second decision gets rid of disadvantages the first one. The main idea of second decision is to put function to logable context.
Let’s have a look to code:

Static method of defined at LogableFunction. It wrap function and make it as logable one. Logable function have additional methods to log messages before and after function execution. Therefore wrapped function gets new feature — logging input or output values.
Log output is added by function composition at LogableFunction. You can make function composition as many times as you want. Logable function is still function because it extends java.util.function.Function interface. It is very useful because you can make any Function as Logable. Let’s look on example:

Conclusion
Let’s sum up article’s main points.
- There are two common matters about log messages:
- How program executes
- What values are computed
- There are three places to log function execution:
- Log function input value
- Log function output value
- Log function internal process details
- You can use PeekLog function in order to embed log statements into method’s chain at functional code style
- You can put your function into logable context. Function at logable context gets new feature — logging input or output values.
All code samples you can find at my repository on Github.com
